OpenAI released an open source Neural Network called Whisper for speech recognition with very good performance on different languages and specifically English. Code and models for this Neural Network are available publically. It is trained on 680,000 hours of supervised audio data to handle different accents, background noise and technical language. It can work with different languages and can also translate between different languages.
It splits the audio in 30 second chunk and pass it to an Encoder. A decoder then creates caption/text from tokens. You can view more details on architecture and other dataset details on OpenAI website.
https://openai.com/blog/whisper/
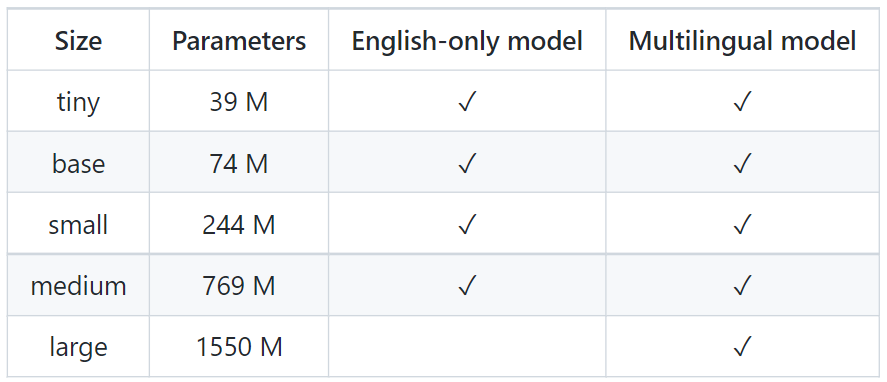
There are 9 models in whisper with different size and language support. Whisper offers both Multilingual and English-only models.
In this tutorial, we will use pretrained models from OpenAI and perform inference on different languages with different accent and noise levels.
Setup
First, we install required packages for to process audio files and get transcribed text. Whisper requires Pytorch (CPU or GPU) and ffmpeg installation. First install required packages to use models from Whisper repository. You can install Pytorch from pytorch official getting started page with CPU or GPU version.
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# Install Whisper
pip install git+https://github.com/openai/whisper.gitUsage
Now, we can load models using whisper and perform tanscription. Use .en with models to use english-only models when loading a model.
import whisper
model = whisper.load_model("base")
# transcribe
result = model.transcribe("filename.mp3")# Output (Clipped)
{
'text': " Open the Cloud Storage Browser and the Google Cloud Platform Console and click Create Bucket. Give the bucket a globally ...",
'segments': [...] # List of segments
}model.transcribe(filename) returns transcription and list of segments with timestamps. We can use that to further process data.
Detect Language
Whisper uses first 30 seconds of file to detect language if not provided, we can also use whiper to detect language of first 30 seconds or any chunk of audio.
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("test.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# Output: Detected language: enTranslate
If audio is another language, whisper also offers feature to convert it to another language. For example, if audio is in spanish, we can easily transcribe and translate to english in same method.
model.transcribe("file.mp3", task="translate")We can also use whisper in CMD for processing files. It offers different outputs like srt, vvt and txt formats. We can also specify models to use for processing files.
whisper audio.mp3 --model baseThere are complete performance details available for each language on github page. You can download different models and perform different operations based on language. For more information on whisper, check github page or try on huggingface.